僕が開発した、プログラミング言語もどきです。Webからのデータ取得に特化した言語です。宣言型で関数型なので、データ取得に関してはやりたいこと中心に書けます。プログラミングのコード自体は、Visual Studioで書くように設計されています。
使い方は、次に示す、クライアントツールから、ソースコードを実行するだけです。あいにくWindows専用です。
rawler から、「ファイル名を指定して実行」を押してソフトをインストール。
インターネットエクスプローラー(IE)を使うと、一手間省けて楽に行えます。 危険だと警告が出ますが、構わず実行。
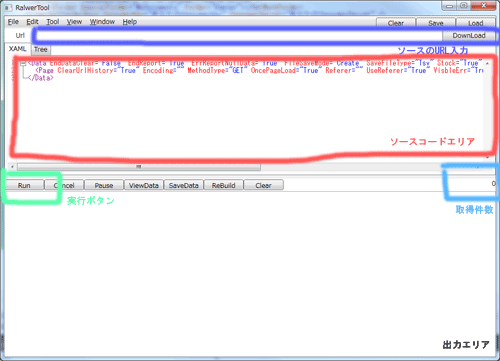
画面構成はこのようになっている。
URL入力
RawlerのソースコードをダウンロードするためのURLを入力するところです。
ソースコード
実行するRawlerのコードを記述するところです。実際は、ダウンロードしたコードの微修正を行います。
実行ボタン
ソースコードを実行します。キャンセル一時停止などは、適切に動いかないので、止めたいときは、ソフトを落としてください。
取得件数
取得したデータの件数を表示します。動いているかの判別に使います。
出力画面
途中経過やエラーなどを出力する画面です。
http://kiichi.azurewebsites.net/RawlerSample/twittersearch.txt URL入力のテキストボックにこのURLを入力してダウンロード(URLをコピーするといい)
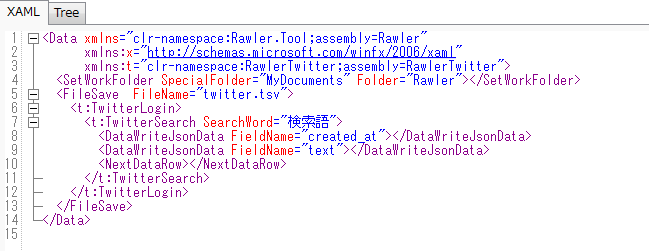
ここの検索語のところを自身の検索したい語に書き換える。 そして、「Run」ボタンを押すと実行される。
初めて実行するときは、Twitterの認証をしなくてはなりません。
ブラウザが立ち上がるので、ツイッターの認証をします。 認証後、数字が表示されるはずです。
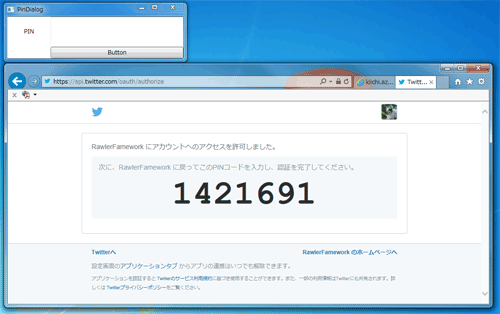
その数字を立ち上がっているPINダイアログに入力しボタンを押します。 これは、一度だけで十分なはずです。
そうするとTwitterの検索からツイートの取得が行われます。
このツイート検索から取得された結果は、「マイドキュメント」の「Rawler」フォルダの「twitter.tsv」に保存されています。 これは、スクリプトの
<SetWorkFolder SpecialFolder="MyDocuments" Folder="Rawler"></SetWorkFolder>
ここで、作業フォルダの指定。
<FileSave FileName="twitter.tsv">
ここで、保存先を指定してるためです。
そのため、これを書き換えると、データの保存先が変わります。
ツイッターからのデータを取得する方法です。
http://kiichi.azurewebsites.net/RawlerSample/tweet.txt ここのスクリプトをダウンロード。
<t:TweetUserTimeline ScreenName="kiichi54321" MaxCount="3500">
ここのScreenNameを欲しいTwitterUserのScreenNameにすると取得できます。
現在の認証では、通常のTwitter認証を使っています。通常のTwitterアプリと同じであり、大量のデータを取ろうとすると、API制限に引っかかり、足かせになります。
そのため、TwitterAPIキーを取得し、若干制限がゆるめの方法を用いてデータを取得します。
ツイッターにログインしている状態でここにアクセスします。
「Create New App」ボタンを押します。
テキトウに入力します。電話認証が必要みたいです。面倒ですね。
作成後、「Keys and AccessToken」から、アクセストークンを調べます。
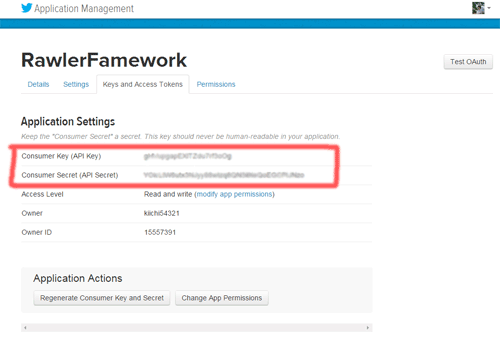
赤く囲ったところです。
<t:SetTwitterApiKeys ConsumerKey="あなたのConsumerKey" ConsumerSecret="あなたのConsumerSecret" />
これを、「SetWorkFolder」の次に書いてください。そして、ここを先ほど調べたアクセストークンを入力してください。 これがTwiiterLoginより前にあるとき、これに基づき、AppOnly認証をします。
AppOnly認証は、Apiを打てる回数が増える代わりに、鍵アカウントの取得は不可能になります。鍵アカウントのデータも欲しい時は、初めに行った、通常の認証を使いましょう。
http://kiichi.azurewebsites.net/RawlerSample/twittersearch3.txt
これをRawlerでダウンロードして、 「SetTwitterApiKeys」に適切なAPIキーの入力と「SetTempVar」に検索語をカンマ区切りで入力してください。(全角のカンマはダメです。必ず半角にしてください)
そして、実行すると、複数の検索語についてツイッター検索が行われます。
これも「マイドキュメント」の「Rawler」フォルダに「twitter2.tsv」というファイルが生成されます。保存先の名前等を変えたいときは適宜替えてください。
また、今回からは、取得できる他のフィールドも書き込むようにしました。
<DataWriteJsonData FieldName="created_at"></DataWriteJsonData>
<DataWriteJsonData FieldName="text"></DataWriteJsonData>
<DataWriteJsonData FieldName="user.id"></DataWriteJsonData>
<DataWriteJsonData FieldName="user.screen_name"></DataWriteJsonData>
<DataWriteJsonData FieldName="user.profile_image_url"></DataWriteJsonData>
<DataWriteJsonData FieldName="user.lang"></DataWriteJsonData>
<DataWriteJsonData FieldName="id"></DataWriteJsonData>
ここです。これは、ツイッターAPIが返すJsonに対応しています。使うのはここらへんかなと思います。 特にいらないと思った列は、消してください。そうすると保存はされません。
http://kiichi.azurewebsites.net/RawlerSample/twittersearch4.txt
このようにLoopで囲むと、無限ループとして、複数の検索語で、最新のものを取得することができます。 実際運用していないので、ほんとにどこまでうまくいくのかよくわかりませんね・・・。
止め方は、ソフト自体を落としてください。
昔、半沢直樹の公式アカウントをフォローしている人のつぶやきの分析をしましたが、これと同じことがこれでできます。
http://kiichi.azurewebsites.net/RawlerSample/twittersearch5.txt
同様に、APIKeyを入力してください。鍵アカウントを欲しいなら、消して通常の認証にします。
対象のツイッターのScreenNameを指定してください。初めは、僕のになっています(kiichi54321)
実行すると、マイドキュメントのTweetDataというフォルダに、入力したScreenNameに基づいたフォルダが作られ、そこにフォローされているアカウントのつぶやきを300個ずつ取得します。
はじめの設定では、最新の300ツイートを取得するようにしています。 この300という数は、中盤くらいにある、
<t:TweetUserTimeline ParentUserIdType="UsetId" SleepSecond="1.2" MaxCount="300">
ここの「MaxCount="300"」によって指定しています。最大限(制限上、おそらく3200件)を取りたい場合は、次のように、その記述を消します。
<t:TweetUserTimeline ParentUserIdType="UsetId" SleepSecond="1.2" >
この取得は長時間かかる可能性があるので、一度停止しても、続きから取得できるような仕組みになっています。 続きからの取得をしたくない場合は、ScreenNameのフォルダを消すか、フォルダの名前の変更、フォルダの移動をしてください。